May 12, 2025 · 12 min read
Mind the Trust Gap: Fast, Private Local-to-Cloud LLM Chat
TL;DR: The messages we send to and receive from LLMs can often be quite private. Right now, these messages sit as plain text in the cloud, open to inspection or storage. Current privacy techniques either degrade quality or are several orders of magnitude slower. We explore an alternative Trusted-Execution-Environment (TEE) protocol with messages decrypted only inside a remote confidential computing environment ("enclave"). Our approach includes: (1) an ephemeral key exchange between the client and remote enclave to derive a shared secret; (2) attestation, where the enclave proves it’s a genuine H100 running in Confidential Computing mode; (3) encrypted, signed, and nonce-protected message passing; and (4) inference entirely within the enclave, where prompts are decrypted and processed securely. The latency implications are negligble: once you use a large enough model like Qwen-32B and long inputs (~8k tokens), the TEE adds just less than 1% latency overhead. Confidential chat is no longer a fantasy. We share an open-source prototype and invite contributions.
Our goals with this blogpost are threefold:
-
Document our exploration of secure inference systems
-
Share lessons learned with a focus on their practical feasibility and efficiency
-
Release open-source prototypes that inspire additional work.
We’ve always had a thing for cloud providers 😊
A couple of months ago, we launched Minions (💻GitHub)—a protocol where small local LMs collaborate with frontier LMs in the cloud to solve tasks on local data. Our paper, to appear in ICML 2025, shows that such protocols can reduce cloud API costs by 5–30X with little to no quality loss.
Though the paper focused on the cost-quality tradeoff, most user feedback boiled down to one thing:
Can you chat privately with a cloud-hosted LLM?

People wanted us to push further:
-
Can we make sure no identifying data ever leaves the device?
-
Can we encrypt all communication between local and cloud environments?
-
Can we prevent inference providers from accessing any plain text inputs and outputs?
Excited about these questions, we sought out to ask: does security come at the expense of efficiency?
Plus, there were clear tailwinds: secure confidential Nvidia GPUs were finally available through Azure. Communication protocols like ❤️ MCP were gaining traction—but they lacked security. And collaborative LLM inference across local/cloud environments (i.e., Minions) were popping up.
Please trust no one. Not us and especially not our AI overlords 🙂
We are motivated by a future where data centers dot the globe, and we want to be able to move intelligence to wherever computation is cheap and fast. We envision this as a force that can democratize intelligence, enabling collective progress worldwide. However, to get there, we need a way to run LLMs anywhere without compromising trust and ensuring secure data center inference.
We got to work–starting by defining a precise threat model. In our setting we explicitly do not trust the cloud provider. Nor do we trust the datacenter operators—who might be third parties located in other countries and control the physical infrastructure. We don’t want either party to access LLM inputs, outputs, or intermediate model activations—ever. To do so, they’d have to take explicit, malicious actions to compromise hardware or software security.
However, we do trust the local client and assume that attackers cannot run code on local machine. We also do trust the silicon manufacturers and their firmware (in this case, NVIDIA and AMD). Put differently, in Jensen and Lisa We Trust.

Note: due to practical constraints on hardware availability, the experiments below were run on Azure ND H100 v5 (confidential computing), which runs closed-source VM code and a full operating system, so the demo actually requires trust in Azure. In principle, for the computation to be secure from the cloud provider, one needs to either use a transparent VM code or bring their own virtualization stack (and a trusted OS). The blog proceeds assuming this setting.
So, we locked things down—for real.
Luckily, Jensen gave us something new to play with: the NVIDIA Hopper H100—the first GPU to support confidential computing (CGPU). In this mode, all code and data on the GPU are encrypted and isolated in a hardware-enforced "enclave" that spans the entire chip, including SMs and HBM. The H100 executes kernels that are launched from a CPU process running the LLM inference server. That CPU process handles the sensitive plaintext, tokenization, and model weights. Therefore, it is critical that the CPU itself acts as an enclave that encrypts all guest code and memory against the host OS. So it is common to use an AMD EPYC 4-Gen “Turin” + SEV-SNP to run the process, and in addition encrypt all information transferred between the CPU and GPU. Such a setup is defacto two nested Trusted Execution Environments (TEEs). TEEs were first developed in the early 2000s to protect secrets inside isolated processor zones. But securing end-to-end LLM inference—from local device to cloud CGPU—takes more than just spinning up a confidential H100 + AMD SEV-SNP (confidential computing mode). The whole pipeline, including message transmission from local machine, needs to be locked down. No off-the-shelf code existed.
So we built a prototype: a three-layer protocol that extends the core TEE guarantees—confidentiality, integrity, and authenticity—across the entire communication pipeline.
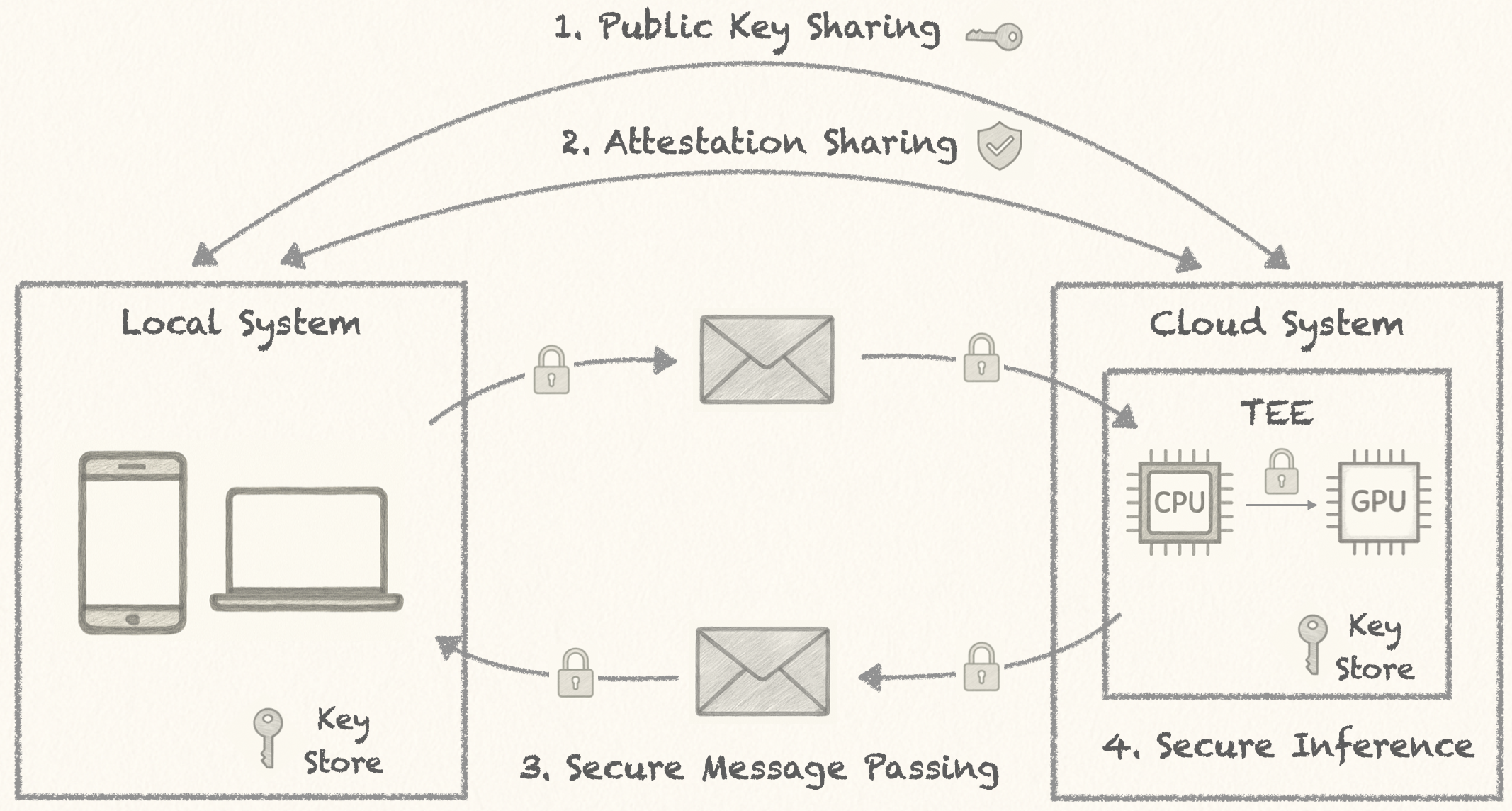
Here is the procedure we implemented, following standard practices:
-
Ephemeral key exchange: The client (on your laptop or edge box) generates a fresh key pair for the session and performs key exchange with the enclave (the CPU), deriving a shared secret. The clients are communicating via HTTPS.
-
Attestation: Before any data is exchanged, the client requests an attestation quote from the CPU and GPU. The server proves, using keys burnt at manufacture, that it runs genuine AMD SEV-SNP with a specific VM ID, as well as a real H100, both running in confidential mode. This attestation report is signed by a unique public key that identifies the remote client.
-
Encrypted Message Passing: All subsequent messages are end-to-end encrypted and signed using HTTPs, ensuring confidentiality, authenticity, and replay protection via nonces.
-
Inference in a TEE enclave: The encrypted user prompts are decrypted only inside the CPU enclave, and inference is executed securely inside the nested TEE. Responses are encrypted and signed before leaving the enclave.
Security guarantees provided by the full protocol:
-
Authenticity The client verifies that the inference server is genuine and running the expected, untampered code inside a TEE. This process prevents attackers from impersonating the server or tricking the client into connecting to a less secure system.
-
Confidentiality Only the secure enclave can decrypt and process user data. Even the server operator or cloud provider cannot access the plaintext prompts or responses (again, assuming user either runs or inspects the virtualization code). Because we use ephemeral key exchange (a new key for every session), even if long-term keys are ever compromised in the future, past conversations remain private.
-
Integrity All messages are signed to prevent tampering while they travel between client and server. We also use a simple counter, called a nonce, which makes sure that old or duplicated messages can’t be resent or rearranged by an attacker. All decryption and verification happens inside the enclave, protecting the system from man-in-the-middle attacks.
Summary: Confidential GPUs (with NVIDIA H100 + AMD SEV-SNP) can run in a special “confidential mode” where everything—from model weights to user prompts—is processed inside an enclave which encrypts all memory and communication, and blocks any outside access—even from the cloud provider or datacenter. We wrap this in an attested, encrypted tunnel, so that user data stays private from local to remote.
Ok ok. We’re secure. But… probably slow AF?
We have shown that we can grab a confidential H100 + AMD SEV-SNP, and add a few extra standard steps on the client side to secure the entire chat. But our primary question is: what are the performance implications? How does LLM latency look when running on such a nested TEE?
Conceptually, TEEs shouldn’t add much overhead— the kernels executed on a CGPU run just as fast as on a standard GPU. Unlike fully homomorphic encryption, we don’t perform computations on encrypted data; the model sees (tokenized) plain text inside the enclave. But since we are running an LLM server on the CPU, the data and running code are encrypted/decrypted everytime they cross between the CPU and GPU, which might take a toll. Every kernel launch (from CPU to GPU) is encrypted, and any data movement (e.g., logits and tokens) is encrypted. Our findings are as follows:
First, the initial CPU+GPU attestation (combining the remote part, local part, and traveling to the Azure and NVIDIA attestation endpoints) introduces a fixed 2-6 second overhead at the begging of each chat. Second, message encryption and decryption costs are negligible. As theory predicts, they scale with context length at very large payload sizes and add only milliseconds of latency—barely noticeable outside of extreme low-latency use cases like defense or voice.
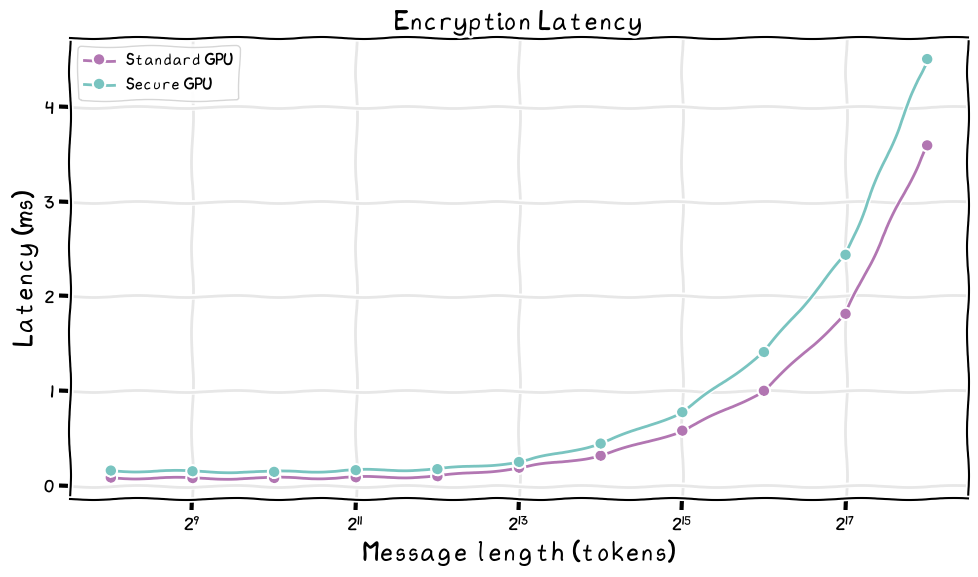

Second, the real performance impact comes from Kernel‑launch frequency and PCIe transfers (see table below):
-
Each kernel launched by the CPU requires data to be encrypted and decrypted between calls.
-
These input/output (I/O) costs can accumulate—but how much depends on the workload.

To measure this, we timed 3B, 8B and 32B parameter models running with and without TEE on a confidential H100, across batch sizes from 1 to 128. We measured Queries Per Second (QPS) as well as overall latency and calculated the percentage overhead introduced by the TEE.
Key findings:
-
Batch sizes 4–16 (typical for online chat apps):
-
3B models → ~28.5% slowdown
-
8B models → ~4.6% slowdown
-
-
Larger models (10B+):
-
Overhead shrinks further because inference compute dominates and security overhead becomes almost “free.”
-
Averaged across batch sizes (prefill 256 tokens, 48 token generation), the secure protocol adds 22% QPS overhead for 3B models and 0.3% QPS overhead for 32B models.
-

-
Batch sizes 32 and above (common in offline/batch inference):
- Overheads increase significantly—but these batch sizes aren’t typical for interactive chat.
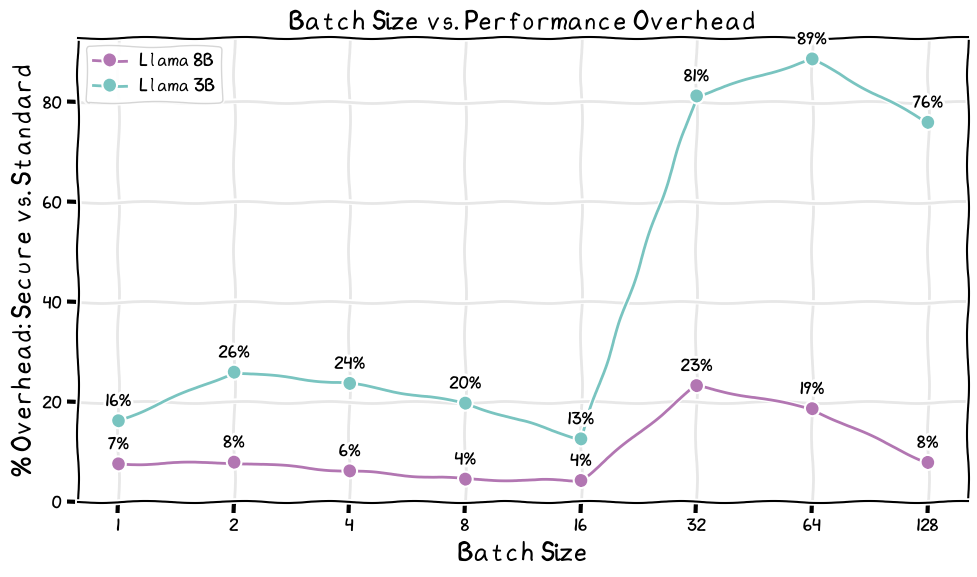
Misc: In batch size = 1 setups, the overhead decreases as prompt length grows. This is because the time spent on LLM inference grows faster than the fixed security costs. Most enterprise workloads use 1,000 to 10,000 tokens, where security overhead remains low.

Bottom line:
No, we are not slow. Security adds 5–22% overhead for small models (3B–8B) and becomes negligible (less than 1% latency overhead, less than 0.3% QPS impact) for models ≥10B parameters.
Lit. Wanna get in on it?
We invite people to join the conversation and build upon our work! We are excited to see what others can do with this protocol.
To make things accessible, we've built a demo chat app (powered by Gemma3-27B) that implements the Minions Secure Chat Protocol. Our initial numbers show that you can run such private LLM chat for large models at reasonable latency: (1) minimal overhead for 10B+ models, and (2) data never leaves the trusted hardware boundary.
- Chat App: Our hosted web app (this demo is just to get a sense of speed. An actual secure chat requires cloning the repo and connecting from a local client, and in addition, verifying the VM code or assuming trust in Azure.)
- Connect locally: Set-up instructions in the Minions repository
We also encourage folks to spin-up their their own secure chats!
- Host your own: Instructions for setting up a secure server
Let's bridge the trust gap together. Please join us on our Minions Discord server.
Pop off girl. Speak your truth 🙏
Cloud providers promise not to inspect or retain user data beyond certain limits—but promises rely on trust. This blog takes a first step toward a different model—one based on security guarantees. We're excited about the emerging possibilities at the intersection of AI systems and applied cryptography. Working with models at such a scale, and running on distributed hardware, poses new questions that require new approaches.
Our work is an exploratory one. We hacked around with this standard protocol and wanted to openly share what we've learned. And we are still learning, so feel free to correct any of our missunderstandings! Stay tuned for our next step, where we'll secure communication across multiple language models running on heterogeneous hardware.
Limitations
Our current implementation for GPU attestation is currently incomplete. The public key we generate for the remote machine is not actually tied to the specific confidential H100, which means we have no way of verifying that the attestation comes from the desired H100. This is an educational post, not a production-ready system, so treat this as a place-holder when building an actual system. Again, we remind the reader that our demo runs on Azure, whereas implementing a full secure chat will require verifying the remote VM code. Moreover, we do not claim to be protecting against active attacks but rather consider a simplistic security setup that allows us to measure latency reliably.
Acknowledgments
We thank Ilan Komargodski, Idan Nurick, and Yael Tauman Kalai for feedback on our approach. We also thank Bill Demirkapi for pointing to limitations in our initial approach and presentation.